"Tell me what to draw and I will improvise wildly. Show me where to draw it and I will suddenly become very professional."
A Diffusion U-Net With a Newfound Respect for Structure
Spatial control adds a second conditioning channel alongside the text prompt: a structural map (edges, depth, or a pose skeleton) that the diffusion model is trained to honor pixel by pixel, while the prompt still decides texture, color, and content. ControlNet achieves this without retraining or damaging the base model by cloning the U-Net's encoder into a trainable branch and wiring it back in through zero-initialized convolutions, so that at the start of training the control branch contributes exactly nothing and the model behaves identically to the original. As training proceeds, the branch learns to nudge the generation toward the supplied structure. The whole idea is a surgical addition to a frozen network, and once you see the zero-convolution trick you will recognize it as a general recipe for adding capabilities to large pretrained models without breaking them.
In Chapter 34 the only handle on a generation was the text prompt, and a prompt is a poor instrument for geometry. You can write "a cathedral" but not "this exact silhouette"; you can write "a person waving" but not "this precise pose." Spatial control closes that gap. Given a structural map derived from a reference (or drawn by hand), a controlled model produces an image whose layout matches the map and whose content matches the prompt. This section builds the mechanism: first the ControlNet architecture and its zero-convolution trick, then the conditioning signals (edges, depth, pose) that come straight from earlier chapters, then the lighter adapter alternatives, and finally the conditioning-scale dial that decides how strictly the model obeys. The opening illustration below captures the shift this chapter makes.

1. The Problem: Prompts Cannot Specify Geometry Beginner
Recall from Section 34.2 how text reaches the image: the prompt is encoded into a sequence of token embeddings, and cross-attention layers in the U-Net let every spatial location query those embeddings. This is a powerful but fundamentally global and semantic channel. The word "left" in a prompt nudges a soft statistical prior; it does not place a pixel. If you need the horizon at row 200, a hand in the lower-right quadrant, or the same composition as a reference photo, no amount of prompt wording reliably delivers it, because the conditioning signal carries meaning, not coordinates.
The fix is to add a conditioning signal that is spatial: a map with the same height and width as the latent grid, where each location carries a structural hint. An edge map says "there is a boundary here." A depth map says "this region is near, that one is far." A pose skeleton says "the elbow is at this coordinate." The model is then trained so that the generated image respects the map. Figure 35.1.1 contrasts the two conditioning channels.
2. ControlNet: A Trainable Copy of the Encoder Intermediate
The naive way to add spatial conditioning would be to fine-tune the whole U-Net on (control map, image) pairs. This is expensive and risky: with limited control data you can damage the rich generative prior that took millions of images to learn, a catastrophic-forgetting failure of exactly the kind Chapter 21 warned about during transfer learning. ControlNet sidesteps the risk with a clean architectural move. It freezes the original U-Net entirely and creates a trainable copy of just the encoder half (the downsampling blocks). The control map is fed into this copy. The copy's outputs are added back into the frozen U-Net's decoder at the corresponding resolutions.
The crucial detail is how the copy connects to the frozen network. Each connection passes through a zero convolution: a $1 \times 1$ convolution whose weights and bias are initialized to zero. Because a zero-initialized layer outputs zero regardless of input, at the very first training step the control branch adds nothing, and the controlled model produces exactly what the original model would. Let $\mathcal{F}$ be a frozen block with parameters $\Theta$, let $\mathcal{F}_c$ be its trainable copy with parameters $\Theta_c$, and let $\mathcal{Z}(\cdot;\,\cdot)$ be a zero convolution. The controlled output of a block on feature $x$ with control input $c$ is
At initialization both zero convolutions output zero, so $y_c = \mathcal{F}(x;\Theta)$ exactly: the network is unchanged. Gradients still flow into the zero convolutions (their input is nonzero), so they begin to learn immediately, but they grow from a safe starting point rather than injecting random noise into a delicate pretrained model. This is why ControlNet trains stably on datasets of only tens of thousands of pairs and rarely degrades the base model's quality. Figure 35.1.2 shows the wiring.
A randomly initialized control branch would, on step one, add structured noise to every layer of a finely-tuned generator and the loss would spike, often unrecoverably. Zero initialization makes the addition start as a no-op and grow only as the data justifies it. This is a general pattern, not a ControlNet quirk: adapters, the residual scaling of deep transformers, and gated additions all rely on starting a new pathway near zero so it cannot harm what already works. When you add a capability to a large pretrained model, initialize the new path so it begins as the identity.
3. Conditioning Signals: Edges, Depth, Pose Intermediate
A ControlNet is trained for one type of control map, so there is a ControlNet for Canny edges, another for depth, another for OpenPose skeletons, and so on. The beautiful part is that the maps themselves come directly from techniques earlier in this book. The Canny edge map is exactly the Canny detector of Chapter 9; the depth map is the output of a monocular depth network from Chapter 27; the pose skeleton is a keypoint detector. The code below uses diffusers to run a Canny-conditioned ControlNet end to end: detect edges, then generate an image that follows them.
# Canny-conditioned ControlNet, end to end: detect edges on a reference,
# then generate an image whose layout follows those edges while the prompt
# decides material and lighting. The edge map is the geometric channel.
import cv2
import numpy as np
import torch
from PIL import Image
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel
# 1. Build the Canny control map from a reference image (Chapter 9 detector).
ref = cv2.imread("reference.jpg")
edges = cv2.Canny(ref, 100, 200) # low/high hysteresis thresholds
edges = np.stack([edges] * 3, axis=-1) # ControlNet expects 3 channels
control = Image.fromarray(edges)
# 2. Load a Canny ControlNet alongside a base Stable Diffusion model.
controlnet = ControlNetModel.from_pretrained(
"lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16)
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"stable-diffusion-v1-5/stable-diffusion-v1-5", controlnet=controlnet,
torch_dtype=torch.float16).to("cuda")
# 3. Generate: the prompt sets content, the edge map sets layout.
image = pipe(
"a sandstone temple at golden hour, photorealistic",
image=control,
num_inference_steps=30,
controlnet_conditioning_scale=1.0, # full obedience to edges
).images[0]
image.save("controlled.png")cv2.Canny call builds the edge map, controlnet_conditioning_scale=1.0 demands full obedience to it, and the output keeps the exact silhouette of reference.jpg but renders it as a sandstone temple, because the edge map fixes geometry while the prompt supplies material and lighting.
Swapping the control type is a two-line change: load sd-controlnet-depth with a depth map, or sd-controlnet-openpose with a pose skeleton. The depth ControlNet is the practitioner's favorite for relighting and style transfer because depth preserves three-dimensional structure while letting surfaces change freely; the pose ControlNet is the standard tool for putting a character in a chosen stance. Because the maps are the very outputs you learned to compute in Parts II and III, the controllable generator is the point where the classical and deep pipelines of this book feed into the generative one.
The most-shared ControlNet demo in early 2023 was not a cathedral or a portrait. It was the trick of hiding a QR code in an image: feed the black-and-white QR pattern as a control map at moderate conditioning scale, prompt for a landscape, and the model paints a scene whose light and dark regions happen to scan as a working QR code. It is a perfect illustration of the conditioning-scale dial in subsection 5, strong enough that a phone can read it, weak enough that it still looks like a mountain.
4. Lighter Alternatives: T2I-Adapter and IP-Adapter Advanced
ControlNet clones half the U-Net, which roughly doubles the parameters that must be loaded and run. Two adapter families trade a little control fidelity for a much smaller footprint. T2I-Adapter uses a small standalone convolutional network (a few million parameters, not a U-Net copy) that extracts features from the control map and adds them into the encoder once, rather than at every block. It is cheaper to train and to run and is strong enough for edge, depth, and sketch control, though slightly less precise than ControlNet on hard structural constraints.
IP-Adapter ("image prompt adapter") solves a different problem: conditioning on an image rather than a structural map. It encodes a reference image with CLIP (the CLIP encoder of Chapter 25) and adds a decoupled cross-attention path, a second set of attention layers that attend to the image embedding in parallel with the text cross-attention. This lets you say "generate in the style of this picture" or "keep this face" by supplying an example image alongside the text. The decoupling is what makes it compose cleanly: the text path and the image path each have their own attention, so the model can follow a prompt and a reference image at once. The snippet shows IP-Adapter style conditioning.
# IP-Adapter conditioning: condition on a reference IMAGE rather than a
# structural map. CLIP encodes the reference and a decoupled cross-attention
# path lets the model follow both the text prompt and the picture at once.
from diffusers import StableDiffusionPipeline
from diffusers.utils import load_image
import torch
pipe = StableDiffusionPipeline.from_pretrained(
"stable-diffusion-v1-5/stable-diffusion-v1-5", torch_dtype=torch.float16).to("cuda")
# Attach an IP-Adapter: a decoupled image cross-attention path.
pipe.load_ip_adapter("h94/IP-Adapter", subfolder="models",
weight_name="ip-adapter_sd15.bin")
pipe.set_ip_adapter_scale(0.6) # how strongly the image prompt acts
style_ref = load_image("style_reference.png") # the image to imitate
image = pipe(
prompt="a fox sitting in a forest clearing",
ip_adapter_image=style_ref, # image conditioning, not a control map
num_inference_steps=30,
).images[0]load_ip_adapter call attaches the decoupled image cross-attention path, the text prompt sets the subject (a fox), and style_reference.png supplies the visual style. The set_ip_adapter_scale(0.6) dial controls how much the reference image pulls the result, the image-domain analogue of the conditioning scale in subsection 5.Implementing ControlNet from scratch means cloning the encoder, wiring zero convolutions into every skip connection, and writing a training loop over control-image pairs, easily three hundred lines plus a training run. In diffusers it is two lines: ControlNetModel.from_pretrained(...) and StableDiffusionControlNetPipeline.from_pretrained(..., controlnet=cn). To stack multiple controls (say edges and depth together), pass a list of ControlNets and a list of conditioning scales; the library handles the per-block addition and the scale weighting internally, including the SDXL and SD3 variants where the block resolutions differ. Build the zero-convolution mechanism once to understand it; in production you load a pretrained ControlNet and supply a map.
5. The Conditioning-Scale Dial Intermediate
Every control method exposes a single most important hyperparameter at inference time: how strongly the control signal acts. In ControlNet it is controlnet_conditioning_scale, a multiplier $\lambda$ applied to the control branch's contribution before it is added into the frozen U-Net. The illustration below makes the tradeoff concrete. Writing the controlled block output with the scale made explicit,
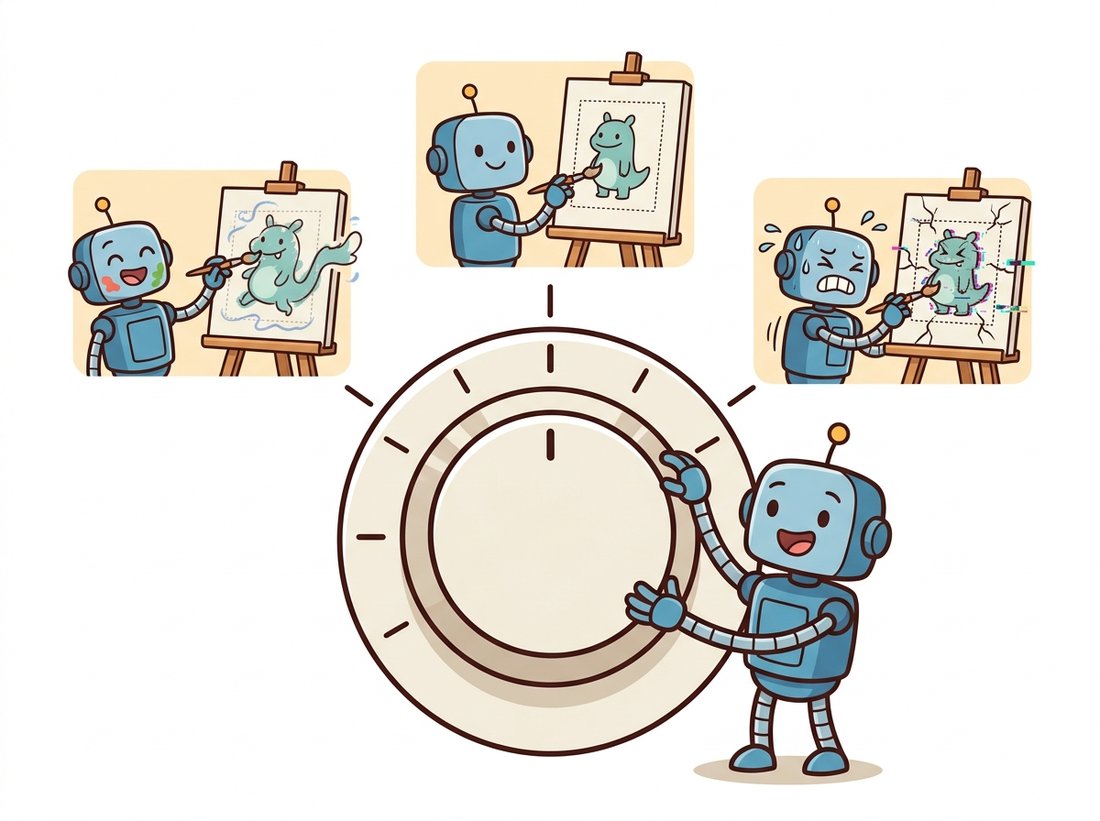
At $\lambda = 0$ the control branch is silent and you get an ordinary text-to-image generation. At $\lambda = 1$ the model follows the structure as trained. Pushing beyond $1$ forces ever-stricter adherence to the map, at the cost of artifacts where the prompt and the structure disagree (the model is being asked to satisfy a geometry that its content prior resists). Below $1$ the structure becomes a suggestion the model may bend. The right value depends on the task: a precise architectural render wants $\lambda$ near $1.0$, while loose compositional guidance often looks best near $0.5$. There is also a guidance start and end control that applies the conditioning only during a window of the sampling steps, since the early steps fix coarse layout and the late steps add detail. The one-line rule of thumb to remember is obedience, not quality: $\lambda$ trades how strictly the map is followed against how freely the prompt invents, and the best setting is the smallest $\lambda$ that pins the structure you care about.
It is tempting to read controlnet_conditioning_scale as an image-quality knob where higher means better, and to set it above $1$ for "more accurate" results. In fact it is purely a tradeoff between obedience to the structural map and the model's content prior, with no notion of quality at all. Pushing $\lambda$ above $1$ forces the generation to trace the edge or depth map even where the prompt's content disagrees, which produces more artifacts (warped textures, smeared boundaries, impossible geometry), not a cleaner image. A blurry or off result at $\lambda = 1.4$ is usually a sign to lower the scale, not raise it. The right value is the smallest one that pins the structure you actually care about and leaves the rest free.
Who: the content team at a mid-size online furniture retailer, 2024. Situation: every product needed a dozen lifestyle shots (the same sofa in a loft, a cottage, a minimalist apartment), and renting and styling physical sets cost thousands per product. Problem: plain text-to-image could produce beautiful rooms but never their sofa; the geometry and proportions drifted every time, and customers complained that the photo did not match the delivered item. Decision: they ran a depth ControlNet conditioned on a single clean studio render of each sofa, varying only the prompt to change the surrounding room and lighting. The depth map pinned the sofa's exact three-dimensional shape while the prompt redecorated everything around it. Result: consistent product geometry across every lifestyle variation, with conditioning scale tuned to about $1.1$ so the sofa stayed rigid while the room stayed free, cutting per-product photography cost by an order of magnitude. Lesson: when one element must stay fixed and the rest must vary, spatial conditioning on the fixed element is far more reliable than trying to describe it in words.
The furniture-catalog story above is a buildable weekend project. Take one clean studio photo of a single object, run a monocular depth network from Chapter 27 to get its depth map, then drive a depth ControlNet with that map while varying only the prompt to place the object in a dozen scenes (a loft, a cottage, a sunlit cafe). The depth map pins the object's three-dimensional shape, so its proportions stay fixed while the room and lighting change, the exact obedience-versus-freedom tradeoff of subsection 5 tuned near $\lambda = 1.1$. Wrap it as a function that takes a product photo and a list of scene prompts and returns a contact sheet of consistent lifestyle shots. This differs from the chapter lab, which locks layout to Canny edges rather than depth, and it gives you a portfolio piece that mirrors what e-commerce teams actually ship.
The 2023 ControlNet design adds a cloned encoder, which is heavy. The frontier through 2024 and 2025 is making control cheaper and more general. ControlNet-LoRA and the unified ControlNet++ line shrink the branch with low-rank factorization. ControlNeXt (2024, arXiv:2408.06070) replaces the encoder copy with a tiny convolutional selector and a normalization-based injection, cutting trainable parameters by up to ninety percent while matching quality. On the architecture side, the diffusion-transformer models of Section 34.3 (SD3, FLUX) fold control directly into the token stream: instead of a side branch, control tokens are concatenated to the sequence, and methods like OminiControl (2024, arXiv:2411.15098) and the in-context conditioning of FLUX.1 Kontext treat structure, reference image, and instruction as different token types that the same attention handles uniformly. The trajectory is clear: control is migrating from a bolted-on branch toward a native input modality of the generator.
ControlNet initializes the connecting convolutions to exactly zero, not to small random values. Explain in two or three sentences why a small-but-nonzero initialization would still risk damaging the frozen base model on the first few training steps, and why zero is uniquely safe. Then argue why gradients can still flow into a zero-initialized convolution even though its output is zero, by considering what the convolution's input is.
Using the Canny ControlNet code in subsection 3, fix a reference image, a prompt, and a random seed, then generate at controlnet_conditioning_scale in $\{0.0, 0.3, 0.6, 1.0, 1.4\}$. Lay the five results out in a row. Describe how the output transitions from "ignores the edges" to "rigidly traces the edges, with artifacts," and identify which value gives the best balance for your image. Repeat with the depth ControlNet and note how the sweet spot differs.
You are deploying a control-conditioned generator to a service that must run on a single 12 GB GPU and serve many concurrent users. Compare ControlNet and T2I-Adapter on parameter count, inference memory, and structural fidelity, citing the mechanism of each (encoder clone with per-block injection versus a small standalone network injected once). Recommend one for this deployment and one situation where you would switch to the other, and justify each choice in a short paragraph.