"I never ask where a pixel is going. I stand at the destination and ask where it came from. People call it pessimism; I call it complete coverage."
A Contrarian Inverse Mapper
Every production warp runs backwards: it iterates over the pixels of the output image and uses the inverse transform to ask where each one came from in the input. This single design decision eliminates the holes and pile-ups that plague the intuitive forward approach, and it generalizes beautifully: once the "where did I come from" question is answered by an arbitrary per-pixel lookup table instead of a matrix, the same machinery performs lens undistortion, fisheye correction, artistic distortions, and the differentiable warps inside neural networks.
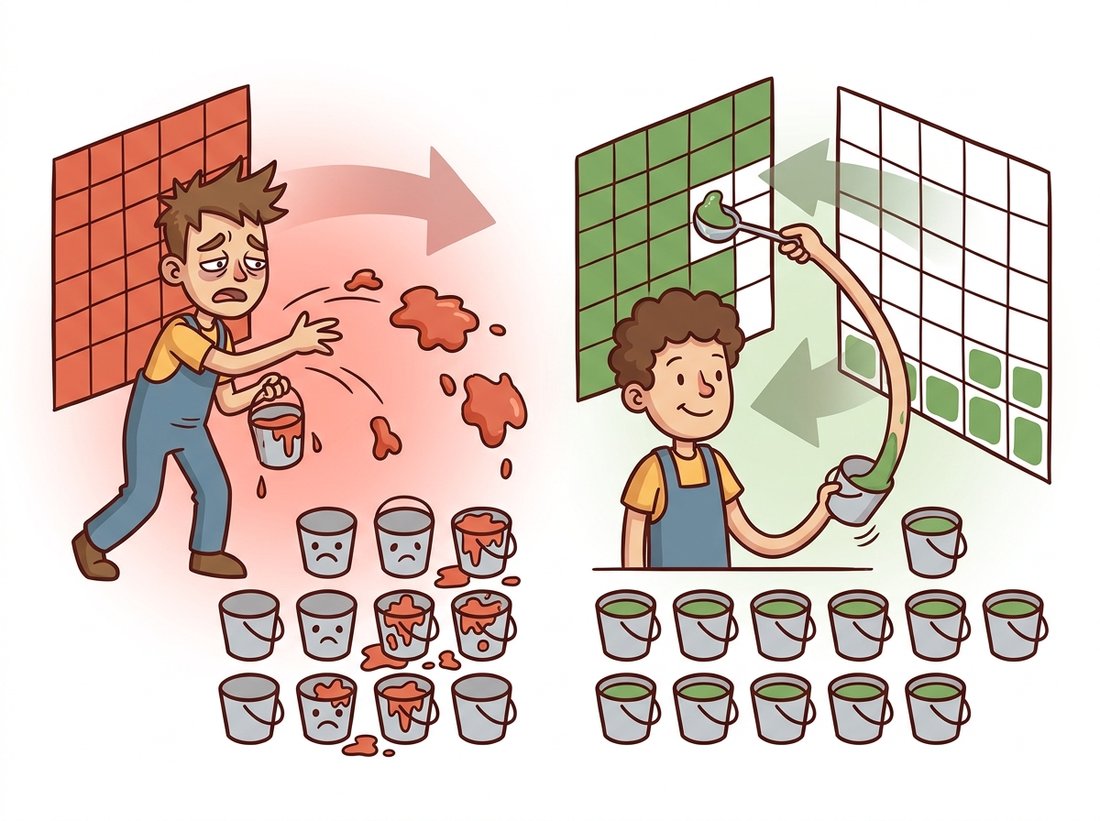
We now hold both halves of the puzzle: Section 5.2 gave us matrices that map coordinates, and Section 5.3 gave us interpolation to read values at the fractional positions those matrices produce. This section assembles them into the actual algorithm that executes a warp, and the assembly contains the chapter's most important engineering idea. It is not obvious, most newcomers implement the wrong version first, and the right version is one line of insight: loop over the output, not the input. The illustration below contrasts the messy forward approach with the clean inverse one.
1. Forward Mapping and Why It Fails Intermediate
The intuitive algorithm reads: for each input pixel $(x, y)$, compute its destination $(x', y') = M(x, y)$, round to the nearest grid position, and copy the value there. This is forward mapping (also called splatting), and it has two failure modes that are not edge cases but guarantees. First, holes: under any transform that locally magnifies, neighboring input pixels land more than one pixel apart in the output, leaving destination pixels that no input pixel ever claims. Rotate by 15 degrees and the output is peppered with unwritten black dots. Second, collisions: under local minification, several input pixels round to the same destination and overwrite one another arbitrarily, last-writer-wins, which is both lossy and nondeterministic with parallel execution.
Inverse mapping flips the iteration. For each output pixel $(x', y')$, compute the source location via the inverse transform, $(x, y) = M^{-1}(x', y')$, and interpolate the input there:
$$ I_{\text{out}}(x', y') \;=\; \mathrm{interp}\!\left(I_{\text{in}},\; M^{-1}(x', y')\right) $$Every output pixel is visited exactly once, so there are no holes and no collisions by construction. The fractional source position is exactly what the bilinear sampler from Section 5.3 was built for. The only requirement is an invertible transform, which every family in Section 5.1's hierarchy satisfies. Figure 5.4.1 contrasts the two strategies; it is the diagram to redraw from memory if you remember only one from this chapter.
"Iterate over what you must fill, pull from what you have" is a pattern far bigger than warping: ray tracers cast rays from the screen into the scene, texture mapping samples the texture per screen pixel, and grid_sample in deep learning warps feature maps by exactly this gather operation. Forward "scatter" approaches do exist (additive splatting with normalization solves the collision problem and appears in point-cloud rendering and frame interpolation), but they are the specialist tool. When you sit down to write any resampling code, your first question should be: what is my output grid, and what do I pull onto it?
2. Building warpAffine From Scratch Intermediate
Inverse mapping plus the vectorized bilinear_sample from Section 5.3 yields a complete affine warper in under 20 lines. The only new machinery is generating all output coordinates at once with np.mgrid and pushing them through the inverted matrix in a single einsum:
# Inverse-mapping warp: build the output coordinate grid, push every
# pixel backwards through the inverted matrix, and read the source with
# the bilinear sampler. Looping over the output is what avoids holes.
import numpy as np
def warp_affine_scratch(img, M2x3, out_shape):
"""Inverse-mapping affine warp of a grayscale image.
M2x3 maps INPUT coords to OUTPUT coords (like cv2.warpAffine).
"""
H_out, W_out = out_shape
M3 = np.vstack([M2x3, [0.0, 0.0, 1.0]]) # lift to 3x3
Minv = np.linalg.inv(M3) # output -> input
ys, xs = np.mgrid[0:H_out, 0:W_out].astype(np.float64)
ones = np.ones_like(xs)
dst = np.stack([xs, ys, ones]) # 3 x H x W homogeneous grid
src = np.einsum('ij,jhw->ihw', Minv, dst) # apply Minv to every pixel
src_x, src_y = src[0], src[1] # affine: w stays 1, no divide
out = bilinear_sample(img, src_x, src_y) # Section 5.3's sampler
# Mask coordinates that fell outside the source image (constant border).
inside = ((src_x >= 0) & (src_x <= img.shape[1] - 1) &
(src_y >= 0) & (src_y <= img.shape[0] - 1))
return np.where(inside, out, 0.0)
Three details in Code 5.4.1 deserve attention. First, the matrix we invert is the input-to-output transform, matching OpenCV's convention; the algorithm itself consumes the output-to-input direction, and APIs differ on which one they want (OpenCV's warpAffine accepts flags=cv2.WARP_INVERSE_MAP to skip the inversion). Second, the einsum applies a single $3 \times 3$ matrix to millions of coordinates with no Python loop; this is the vectorization habit from Chapter 0 doing real work. Third, the inside mask implements the simplest border policy: pixels whose source falls outside the input become black. These are the same border questions you met when convolution kernels hung off the image edge in Chapter 3, and OpenCV reuses the identical flags: BORDER_CONSTANT, BORDER_REPLICATE, BORDER_REFLECT_101, and for tiling warps, BORDER_WRAP.
Our 20-line warper, extended to color, multiple interpolation kernels, all border modes, and SIMD speed, is what these two calls deliver in one line each:
# The production equivalents of the from-scratch warper: warpAffine for
# 2x3 affine matrices, warpPerspective for 3x3 homographies. Interpolation
# kernel and border policy are passed as flags rather than coded by hand.
out = cv2.warpAffine(img, M2x3, (W_out, H_out),
flags=cv2.INTER_LINEAR,
borderMode=cv2.BORDER_REPLICATE)
out = cv2.warpPerspective(img, H3x3, (W_out, H_out)) # homography version
Roughly 20 lines (or 60 with bicubic and border modes) become 1. Internally OpenCV tiles the output, computes source coordinates in fixed-point arithmetic, dispatches SIMD-vectorized interpolation per tile, and multithreads across tiles, typically 10-50× faster than our NumPy version. Note the size argument is (width, height), opposite to NumPy's shape order; this asymmetry causes a measurable fraction of all OpenCV bugs.
The algorithm of this section iterates over the output and applies $M^{-1}$ internally, so it is natural to assume you should hand cv2.warpAffine or cv2.warpPerspective the inverted matrix. You should not. By default these functions take the forward input-to-output matrix and invert it themselves; pass np.linalg.inv(M) and you have inverted twice, applying the warp backwards (a clockwise rotation becomes counterclockwise, a zoom-in becomes a zoom-out). The confusion arises because "inverse mapping" names the internal traversal strategy, not the matrix you supply. Two rules keep it straight: feed cv2.warp* the forward matrix unless you set flags=cv2.WARP_INVERSE_MAP; but feed cv2.remap and grid_sample the already-inverted source coordinates, because those consume the output-to-input direction directly.
3. Beyond Matrices: remap and the Lookup-Table View Intermediate
Here is the conceptual jump that makes inverse mapping truly powerful: nothing in the algorithm requires the source coordinates to come from a matrix. Any pair of arrays map_x[y, x] and map_y[y, x], declaring for each output pixel where in the input to look, defines a valid warp. OpenCV exposes exactly this as cv2.remap, and it is the escape hatch for every transform that is not projective: lens distortion, fisheye unwrapping, swirl filters, scanline jitter, and the per-pixel flow fields we will meet in Chapter 15.
The canonical real-world example is radial lens distortion. Real lenses bow straight lines outward (barrel distortion, wide-angle lenses) or inward (pincushion, telephoto). The standard model perturbs each point's distance from the image center: with normalized radius $r$,
$$ r_{\text{distorted}} \;=\; r\,(1 + k_1 r^2 + k_2 r^4) $$
where $k_1, k_2$ are lens-specific coefficients (where they come from is the calibration story of Chapter 12). To undistort, we build maps that send each output (clean) pixel to its distorted source position and let remap do the rest:
# Undistort barrel distortion by building two per-pixel lookup tables and
# handing them to cv2.remap. The radial factor varies with distance from
# the center, so no single matrix could express this warp.
import cv2
import numpy as np
img = cv2.imread("wide_angle.jpg")
h, w = img.shape[:2]
cx, cy = w / 2.0, h / 2.0
k1, k2 = 0.28, 0.06 # barrel distortion strengths (illustrative)
# For each OUTPUT pixel, where in the distorted input is its color?
ys, xs = np.mgrid[0:h, 0:w].astype(np.float32)
xn = (xs - cx) / cx # normalize to roughly [-1, 1]
yn = (ys - cy) / cy
r2 = xn**2 + yn**2
factor = 1 + k1 * r2 + k2 * r2**2
map_x = (xn * factor * cx + cx).astype(np.float32)
map_y = (yn * factor * cy + cy).astype(np.float32)
undistorted = cv2.remap(img, map_x, map_y,
interpolation=cv2.INTER_LINEAR,
borderMode=cv2.BORDER_CONSTANT)
cv2.remap: two float32 lookup tables tell every output pixel where to shop for its value. No matrix could express this warp; the radius factor varies per pixel.
Two performance notes turn this from demo into production. The maps depend only on the lens, not the image, so compute them once and reuse them for every frame of a video stream. And cv2.convertMaps converts the float maps into a fixed-point representation (CV_16SC2) that remap executes significantly faster with identical visual results, a standard trick on embedded hardware.
The map_x / map_y lookup tables of Code 5.4.3 are all you need for a real-time camera-effects app, the kind of toy that doubles as a portfolio piece. Open a webcam stream with cv2.VideoCapture(0), precompute one set of maps per effect once at startup (a pinch that pulls toward the center with factor < 1 near the middle, a bulge with factor > 1, the swirl of Exercise 5.4.2, or a vertical wave $map\_x = x + A\sin(2\pi y / \lambda)$), and run a single cv2.remap per frame inside the capture loop. Because the maps never change, the per-frame cost is pure memory traffic and easily hits 30 frames per second on a laptop. Beginner, about 45 minutes. The advanced version turns it into a real lens-correction tool: calibrate your actual webcam in Chapter 12, feed the recovered $k_1, k_2$ into the undistortion maps, and ship a live barrel-distortion fixer. Convert the maps with cv2.convertMaps first, exactly as the parking-camera example below does, and you have a genuinely deployable filter rather than a demo.
Who: A perception engineer at an automotive supplier building a surround-view parking system.
Situation: Four fisheye cameras stream 30 frames per second each; every frame must be undistorted and warped into a common top-down view before stitching, on a power-constrained automotive system-on-chip (SoC).
Problem: The prototype called the full undistortion math per frame, recomputing trigonometric per-pixel maps 120 times a second. The SoC ran at 90 percent CPU before any detection code ran.
Decision: The engineer split the work by what changes: lens geometry never changes, so the maps were precomputed once at startup with cv2.initUndistortRectifyMap (the calibrated-camera version of Code 5.4.3), converted to fixed point with cv2.convertMaps, and the per-frame work reduced to four cv2.remap calls.
Result: Per-frame warp cost dropped by roughly 4×, freeing the budget for the actual parking-spot detection. The visual output was pixel-identical.
Lesson: A warp is a lookup table plus interpolation. If the geometry is static, build the table once; the per-frame cost is then pure memory traffic, which is exactly what embedded silicon is good at.
4. Differentiable Warping: grid_sample Advanced
The same gather-and-interpolate operation lives inside PyTorch as torch.nn.functional.grid_sample, with one crucial addition: it is differentiable. Bilinear interpolation is a little weighted sum, so gradients flow through the weights to the sampling coordinates themselves, which means a network can learn where to look. This was the breakthrough of Spatial Transformer Networks (Jaderberg et al., 2015), and it is now plumbing inside registration networks, optical-flow training, and the view-synthesis methods of Chapter 27.
# The differentiable PyTorch warp: affine_grid turns a matrix into an
# inverse-mapping coordinate grid and grid_sample gathers from it. Because
# the gather is bilinear, gradients flow back to the sampling coordinates.
import torch
import torch.nn.functional as F
img_t = torch.rand(1, 3, 240, 320) # (N, C, H, W)
# grid holds, for each output pixel, the source location in
# NORMALIZED coordinates: x and y each in [-1, 1] over the input.
theta = torch.tensor([[[0.966, -0.259, 0.0], # 15-degree rotation,
[0.259, 0.966, 0.0]]]) # expressed for normalized coords
grid = F.affine_grid(theta, size=img_t.shape, align_corners=False)
warped = F.grid_sample(img_t, grid, mode='bilinear',
padding_mode='zeros', align_corners=False)
print(warped.shape) # torch.Size([1, 3, 240, 320])
affine_grid builds the inverse-mapping coordinate grid from a matrix, grid_sample performs the differentiable gather. Both the image and the grid can carry gradients.
The API holds two traps for OpenCV-trained hands. Coordinates are normalized: $(-1, -1)$ is the input's top-left and $(1, 1)$ its bottom-right, so pixel-space maps must be rescaled before use. (The rotation block above needed no rescaling because rotation angles are the same in any coordinate scale; a translation entry, by contrast, would have to be divided by half the image width or height to become a normalized offset, which is a frequent source of "my warp shifted by the wrong amount" bugs.) And the align_corners flag changes what $-1$ and $1$ mean (corner pixel centers versus corner pixel edges); mixing conventions between a model's training code and its deployment code shifts every sample by up to half a pixel, an error small enough to survive code review and large enough to degrade a super-resolution model. Pick align_corners=False (the modern default) and use it everywhere.
The texture-mapping hardware that makes grid_sample fast on GPUs was designed in the 1990s so that video games could wrap brick patterns onto walls. The operation deep learning calls "differentiable image sampling" is, in silicon terms, the same circuit that textured every wall in Quake. Few transistors have had such a distinguished second career.
Differentiable warping has become a load-bearing component across 2024-2026 research. Optical-flow models such as SEA-RAFT (Wang et al., ECCV 2024) are trained by backward-warping one frame toward another through grid_sample and penalizing the photometric residual, making the warp itself the loss function. Video frame interpolation runs the opposite primitive, differentiable forward splatting (softmax splatting, Niklaus and Liu, CVPR 2020), inside modern interpolation and video-generation stacks where occlusions must be resolved by depth-like weights rather than overwritten. And the view-synthesis lineage, from NeRF's ray sampling to 3D Gaussian Splatting (Kerbl et al., SIGGRAPH 2023) and its fast 2024-2025 successors, can be read as the warping question asked in 3D: instead of a 2D lookup table, a learned scene representation answers "where does this output pixel's content come from?" The inverse-versus-forward mapping distinction you learned in this section is precisely the gather-versus-splat distinction these papers negotiate.
5. A Checklist for Production Warps Beginner
Warping code is short but dense with conventions, and most bugs come from the same five questions being answered inconsistently. Before shipping any warp, walk this list:
- Direction: does your API want the forward matrix or the inverse? (
cv2.warp*wants forward and inverts internally;remapandgrid_sampleconsume the inverse-mapped coordinates directly.) - Coordinate convention: pixel coordinates or normalized? $(x, y)$ or (row, col)? Size as (width, height) or shape as (height, width)?
- Interpolation: bilinear for images, nearest for masks and label maps (the phantom-class trap from Section 5.3), and an anti-aliased path if the warp locally minifies.
- Border policy: what value do out-of-source pixels take, and will downstream code mistake it for content? (A black border feeding a histogram skews it; recall the border discussions of Chapter 3.)
- Reuse: if the geometry is fixed, are the maps precomputed and fixed-point converted?
With execution machinery in hand, one question remains open, and it is the big one: where do the transforms come from when no one hands you a matrix? Estimating them from the images themselves is image registration, the subject of Section 5.5.
An image is forward-mapped through a similarity transform with scale $s = 2$ (each axis). Assuming rounding to nearest integer and ignoring borders, what fraction of output pixels receive no value? What if $s = 3$? Now answer for minification at $s = 0.5$: what is the average number of input pixels colliding on each output pixel, and why does "last writer wins" produce aliasing by the argument of Section 5.3's downscaling discussion?
Using the structure of Code 5.4.3, implement a swirl effect: each output pixel samples from the input position obtained by rotating its offset from the image center by an angle $\theta(r) = \theta_{\max}\,(1 - r/R)$ that decays from the center to radius $R$. Apply it to a portrait with cv2.remap at three values of $\theta_{\max}$. Then implement the same warp by forward mapping (round and copy) and display the two results side by side; describe the artifacts you observe and connect each to Figure 5.4.1.
For a 1920×1080 three-channel frame, benchmark four undistortion strategies over 300 iterations: (a) recomputing float maps each frame then remap; (b) precomputed float32 maps; (c) precomputed maps converted with cv2.convertMaps to CV_16SC2; (d) our from-scratch NumPy warper from Code 5.4.1 adapted to use the maps. Report milliseconds per frame and speedup ratios, and profile where strategy (a) spends its time. At what frame rate does each strategy stop being real-time?