"I fit two hundred points beautifully. Then one outlier walked in, and now I'm somewhere I can't explain, and the inliers won't return my calls."
A Least-Squares Fit With Regrets
Detection tells you a line exists; fitting tells you exactly which line, to a fraction of a pixel, and the entire craft of fitting in vision is managing a single tension: the squared loss that is statistically optimal for honest Gaussian noise is unboundedly gullible toward outliers. This section builds the toolkit in escalating order of paranoia: total least squares for the geometry, M-estimators that cap how loudly any point may complain, and RANSAC, which abandons loss-shaping altogether and instead searches for the largest consensus of points that agree on one model. RANSAC is the algorithm to internalize: met here on lines, it returns for match filtering in Chapter 10, fundamental matrices in Chapter 13, and pose estimation in Chapter 14.
The Hough transform of Section 9.3 ended with an answer quantized to its bin width: a line known to within a degree and a pixel. For drawing on a debug image, fine; for steering a vehicle in Section 9.5 or measuring a machined part, not fine. The standard two-step is to let voting detect (and, crucially, collect the supporting pixels) and then let fitting measure, estimating continuous parameters from those supporters at subpixel precision. This section is about doing the second step without being betrayed by the points that should never have been in the set.
1. Least Squares, Two Ways Intermediate
Given points $(x_i, y_i)$ believed to lie on a line, ordinary least squares (OLS) fits $y = mx + b$ by minimizing the squared vertical residuals $\sum_i (y_i - m x_i - b)^2$. That asymmetry, vertical distance rather than distance to the line, is inherited from statistics, where $x$ is an error-free covariate and all the uncertainty lives in $y$. Image geometry obeys no such convention: an edge pixel is noisy in every direction, and a lane line is as likely to be vertical as horizontal. For near-vertical point sets, tiny $x$-noise translates into wild apparent slopes, and OLS systematically flattens the estimate; in the limit of an exactly vertical line, it cannot represent the answer at all, the same pathology that doomed slope-intercept in Section 9.3.
The geometric fix is total least squares (TLS): minimize squared perpendicular distances to the line, the distances that Figure 9.4.1 contrasts with OLS's vertical ones. TLS has a closed form worth knowing by heart. The best line passes through the centroid $\bar{p}$, and writing the unit normal as $\mathbf{n}$, the objective $\sum_i \big( (p_i - \bar{p}) \cdot \mathbf{n} \big)^2 = \mathbf{n}^\top S \, \mathbf{n}$ is a quadratic form in the $2 \times 2$ scatter matrix $S = \sum_i (p_i - \bar{p})(p_i - \bar{p})^\top$. The minimizing $\mathbf{n}$ is the eigenvector of $S$ with the smallest eigenvalue; equivalently the line's direction is the largest-eigenvalue eigenvector.
Why the smallest eigenvalue? For a unit vector $\mathbf{n}$ the quadratic form $\mathbf{n}^\top S\,\mathbf{n}$ is just the variance of the points measured along $\mathbf{n}$, so making it small means pointing $\mathbf{n}$ in the direction the points spread least, which is the direction perpendicular to the line they sit on. (An eigenvector of $S$ is a direction the scatter matrix only stretches, never rotates; its eigenvalue is how much variance the points carry along that direction. The eigenvector and PCA refresher in Appendix A: Mathematical Foundations covers both in a page.) Readers who know PCA will recognize it exactly: the TLS line is the first principal component, anchored at the centroid.
The code makes the difference concrete on a nearly vertical point set with the same isotropic noise in both coordinates:
# Fit the same near-vertical point cloud two ways: OLS minimizes vertical
# residuals and flattens the slope, while TLS (the smallest-eigenvalue
# eigenvector of the scatter matrix) measures perpendicular distance.
import numpy as np
rng = np.random.default_rng(7)
true_angle = 88.0 # nearly vertical line
d = np.deg2rad(true_angle)
t = rng.uniform(-50, 50, 300)
pts = np.c_[t * np.cos(d), t * np.sin(d)] + rng.normal(0, 1.0, (300, 2))
# OLS: regress y on x (vertical residuals)
m, b = np.polyfit(pts[:, 0], pts[:, 1], 1)
# TLS: principal axis of the centered scatter matrix
c = pts - pts.mean(axis=0)
eigval, eigvec = np.linalg.eigh(c.T @ c)
vx, vy = eigvec[:, -1] # largest-eigenvalue direction
print(f"true slope {np.tan(d):8.2f} angle {true_angle:.1f} deg")
print(f"OLS slope {m:8.2f} angle {np.degrees(np.arctan(m)):.1f} deg")
print(f"TLS slope {vy / vx:8.2f} angle {np.degrees(np.arctan2(vy, vx)) % 180:.1f} deg")
# Representative output:
# true slope 28.64 angle 88.0 deg
# OLS slope 14.31 angle 86.0 deg
# TLS slope 28.49 angle 88.0 deg
np.polyfit halves the slope (the textbook attenuation bias), while the largest-eigenvalue eigenvector of c.T @ c recovers the true 88-degree direction; only the residual definition differs between them.
For curves beyond lines the same least-squares machinery extends to anything linear in its parameters: a parabola $x = a y^2 + b y + c$ (the lane-friendly orientation that Section 9.5 will use) builds a design matrix from powers of $y$ and solves the normal equations, which is precisely what np.polyfit does internally, along with scaling tricks that keep the system well conditioned.
2. The Fragility of the Square Intermediate
Why square residuals in the first place? Because under independent Gaussian noise, as modeled in Chapter 7, the least-squares solution is the maximum-likelihood estimate: squaring is not arbitrary, it is the log of the Gaussian density. But the optimality is a contract with an assumption, and image data violates it routinely. The pixels feeding your line fit are not "true line plus Gaussian jitter"; some of them are a glare blob, a leaf, a second structure that wandered into the gate. For such points the Gaussian model assigns probabilities like $10^{-50}$, and the squared loss, dutifully maximizing likelihood, will move the line however far it must to make the absurd point less absurd. Influence grows linearly and without bound in the residual: a point 100 pixels off pulls 100 times harder than a point 1 pixel off. In the robust-statistics vocabulary, least squares has a breakdown point of zero: a single sufficiently bad point produces an arbitrarily bad fit.
3. M-Estimators: Capping the Complaint Advanced
The first family of fixes keeps the optimization framing but swaps the loss $\rho(r)$. The Huber loss is quadratic for $|r| \le \delta$ and linear beyond, so distant points pull with constant rather than growing force; the Tukey biweight goes further and flattens entirely, so far-enough outliers exert zero influence.
Estimators of this family are called M-estimators, and they are solved by iteratively reweighted least squares (IRLS): fit, compute residuals, downweight points with large residuals, refit, repeat until the weights settle. The word "downweight" is precise, not a vibe: minimizing a robust loss $\rho(r)$ is equivalent to solving a weighted least-squares problem with per-point weight $w(r) = \rho'(r)/r$, the slope of the loss divided by the residual.
That single weight formula explains every case at a glance. For the plain square $\rho(r) = r^2$ it gives $w = 2$, a constant, so every point pulls equally and one outlier dominates; for Huber, $w$ stays constant inside the band but falls off as $1/|r|$ outside it, so a point twice as far pulls half as hard; for the redescending Welsch and Tukey losses $w$ decays toward zero, so a far-enough point is multiplied out of the fit entirely. Each IRLS iteration just plugs the current residuals into $w(r)$ and re-solves, which is why the loop converges to the robust optimum. OpenCV packages the whole loop as cv2.fitLine, where the distType argument names the loss:
# Fit one contaminated point set with three M-estimator losses through the
# same cv2.fitLine call, changing only distType, to show how the loss shape
# governs an outlier's influence: quadratic, linear-tailed, then redescending.
import cv2
import numpy as np
rng = np.random.default_rng(0)
# 60 honest points on y = 0.5 x + 10, sigma = 1 px
x = rng.uniform(0, 100, 60)
inliers = np.c_[x, 0.5 * x + 10 + rng.normal(0, 1.0, 60)]
# a glare blob: 6 bad points far below the line (about 9% contamination)
outliers = np.tile([150.0, -120.0], (6, 1)) + rng.normal(0, 2.0, (6, 2))
pts = np.vstack([inliers, outliers]).astype(np.float32)
for name, dist in [("L2 (plain TLS)", cv2.DIST_L2),
("Huber", cv2.DIST_HUBER),
("Welsch", cv2.DIST_WELSCH)]:
vx, vy, x0, y0 = cv2.fitLine(pts, dist, 0, 0.01, 0.01).ravel()
print(f"{name:15s} slope {vy / vx:+.3f}")
# Representative output (true slope +0.500):
# L2 (plain TLS) slope +0.214
# Huber slope +0.487
# Welsch slope +0.499
DIST_L2 surrenders more than half the true slope, DIST_HUBER's linear tails recover most of it, and the redescending DIST_WELSCH loss (a Tukey-style cousin) ignores the blob entirely, all through the same cv2.fitLine call with a different distType.A hand-rolled IRLS (fit, residuals, weights, refit, convergence test) is 25 honest lines and two subtle bugs waiting to happen (weight floor, convergence criterion). cv2.fitLine(pts, cv2.DIST_HUBER, 0, 0.01, 0.01) is one line: OpenCV runs the reweighting internally, exposes six loss functions (DIST_L2, DIST_L1, DIST_L12, DIST_FAIR, DIST_WELSCH, DIST_HUBER), and returns the line as a unit direction plus a point, which is the orientation-neutral representation TLS taught us to prefer. A 25-to-1 reduction, plus the numerical maturity of code that has run in production for two decades.
M-estimators have a ceiling, though. IRLS starts from the plain least-squares fit, and the redescending losses that ignore outliers also ignore anything far from the current fit. If contamination is heavy enough that the starting fit lands closer to the outliers than the truth, the reweighting converges confidently to the wrong structure. In practice M-estimation is excellent up to roughly 10 to 20 percent contamination with a decent initialization. Edge maps routinely do worse: in Section 9.5's lane images, on a bad frame most thresholded pixels can belong to shadows and asphalt texture rather than paint. For that regime you need the second family.
4. RANSAC: Fit the Many, Ignore the Few Advanced
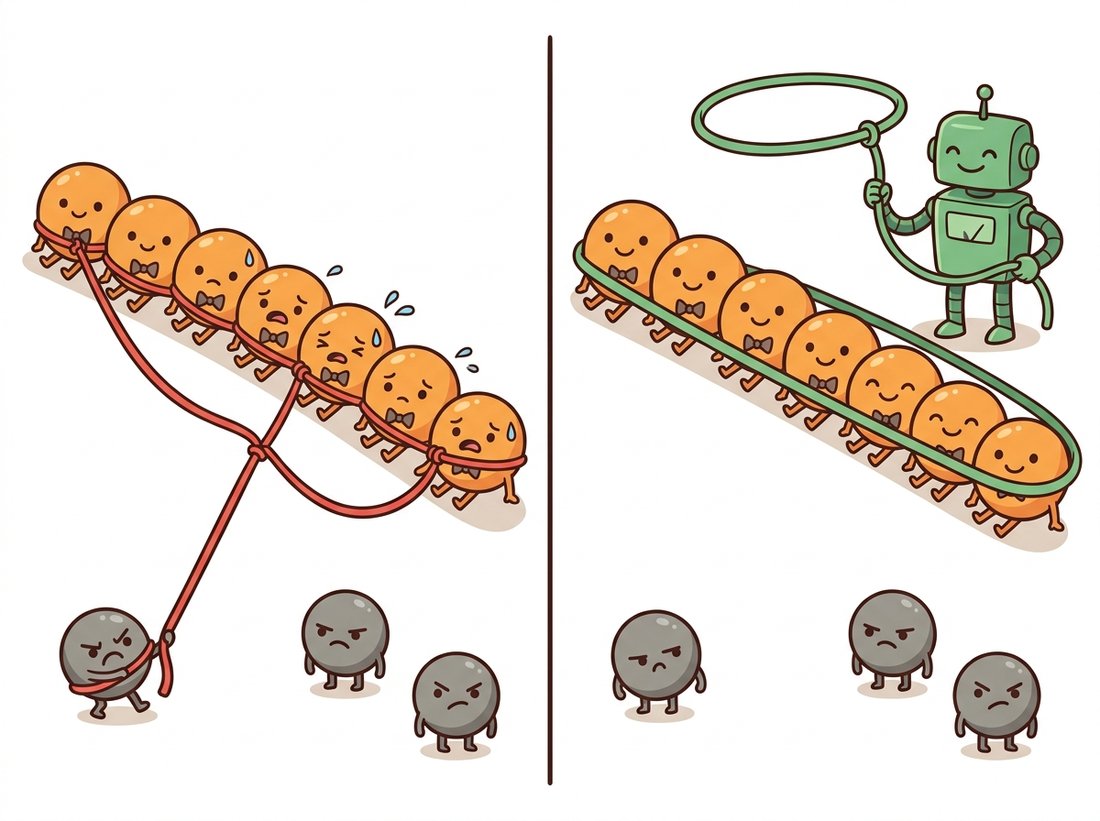
RANSAC (Random Sample Consensus, Fischler and Bolles, 1981) abandons the idea of weighing all points and instead hunts for the largest subset that agrees on one model. The loop is almost embarrassingly simple. Repeat $N$ times: draw the minimal sample that determines the model (2 points for a line, 3 for a circle, 4 correspondences for the homographies of Chapter 5); fit the model to the sample exactly; count the inliers, points within a tolerance $\tau$ of the model. Keep the hypothesis with the most inliers, then refit precisely (TLS or an M-estimator) on its consensus set. Outliers cannot sabotage hypotheses they are not sampled into, and a hypothesis built from two honest points collects the whole honest population as supporters. The illustration below contrasts the two mindsets: least squares ties a rope to every point and gets dragged off course by one stubborn outlier, while RANSAC lassos only the largest agreeing group and lets the troublemakers stay off the ballot.
The number of iterations is not folklore; it is arithmetic. If the inlier fraction is $w$ and the minimal sample has $s$ points, one draw is all-inlier with probability $w^s$, so the number of iterations needed to see at least one clean draw with confidence $p$ (the success probability you demand, typically 0.99 or 0.999) is
$$ N \;=\; \frac{\ln(1 - p)}{\ln(1 - w^s)}. $$
For a line ($s = 2$) with half the points outliers ($w = 0.5$) and $p = 0.99$, $N = 17$: seventeen tries to fit a line through 50 percent garbage, which is why RANSAC feels like cheating the first time it works. The formula's sting is the exponent: for a fundamental matrix with $s = 8$ at $w = 0.5$, $N \approx 1{,}177$, and at $w = 0.3$ it explodes past 70,000, the reason Chapter 13 cares so much about minimal solvers and inlier-rate boosters. Figure 9.4.2 shows the consensus logic that makes the whole thing tick.
The whole loop is shorter than its derivation. The implementation below turns the four bullet steps (sample, fit, count, keep) into twenty lines, then runs the final total-least-squares polish on the winning consensus set, exactly the two-step recipe this section is building toward.
# RANSAC for a 2D line: repeatedly fit a minimal two-point hypothesis,
# score it by how many points fall within tol of the line, keep the
# largest consensus set, then polish with TLS on the inliers only.
import numpy as np
def ransac_line(pts, n_iter=100, tol=2.0, seed=0):
rng = np.random.default_rng(seed)
best_inl = None
for _ in range(n_iter):
i, j = rng.choice(len(pts), size=2, replace=False) # minimal sample
p, q = pts[i], pts[j]
d = q - p
n = np.array([-d[1], d[0]]) / (np.hypot(*d) + 1e-12) # unit normal
resid = np.abs((pts - p) @ n) # point-line dist
inl = resid < tol
if best_inl is None or inl.sum() > best_inl.sum():
best_inl = inl
# final polish: TLS on the consensus set only
sel = pts[best_inl]
c = sel - sel.mean(axis=0)
_, eigvec = np.linalg.eigh(c.T @ c)
return eigvec[:, -1], sel.mean(axis=0), best_inl
# same contaminated data as the cv2.fitLine demo above
direction, centroid, inl = ransac_line(pts)
print(f"inliers found: {inl.sum()}/{len(pts)}, "
f"slope {direction[1] / direction[0]:+.3f}")
# Representative output:
# inliers found: 60/66, slope +0.501
ransac_line draws minimal two-point hypotheses, tests inliers with a perpendicular-distance threshold, maximizes consensus, and runs a final total-least-squares polish restricted to the 60-point consensus set, recovering the true slope to three decimals despite the glare blob that defeated DIST_L2 above.The clean derivation of $N = \ln(1-p)/\ln(1 - w^s)$ invites a false sense of safety: that running $N$ iterations proves RANSAC found the true model. It proves much less. The formula bounds only the probability of drawing one all-inlier minimal sample; turning a clean sample into the correct answer still depends on the tolerance $\tau$ and on $w$ being what you assumed. Set $\tau$ too large and a parallel shadow band gets swallowed into the consensus, so a confident, high-inlier-count fit lands on the wrong structure entirely; set it too small and genuine inliers are rejected and the count collapses. And $w$ is an estimate: if the real inlier fraction is lower than your guess, the computed $N$ is too small and the clean draw may never come. RANSAC returns the largest consensus it happened to find, not a certified global optimum, which is exactly why the recipe always refits and why Section 9.5 adds sanity gates on top: a plausible-looking fit through enough points is not the same as the correct one.
The warning above says $\tau$ is the knob that decides who is an inlier; the fastest way to believe it is to turn it. Take the contaminated point set from Code Fragment 3 and rerun ransac_line with tol sweeping 0.5, 2, 8, 30, printing the inlier count and the recovered slope each time. At a tight tolerance the count stays near the 60 honest points and the slope holds at the true value; widen tol far enough and the glare blob is admitted into the consensus, the count jumps, and the slope drifts toward the contaminated fit, a confident answer built on the wrong roster. That single sweep makes the warning's abstract claim, that a high inlier count is not the same as a correct fit, something you can see in two lines of output.
The first time the iteration formula returns $N = 17$ for a line through data that is half outliers, most people reread it twice. The trick is that RANSAC never tries to please the garbage; it only needs to stumble onto two honest points in the same draw, and a coin-flip inlier rate makes that a one-in-four event. Seventeen flips to see one clean pair is unremarkable arithmetic; it only feels like sorcery because least squares trained us to expect that every bad point gets a vote. RANSAC's quiet cruelty is that the outliers never even make the ballot.
M-estimators and RANSAC answer the outlier problem from opposite ends. M-estimators keep everyone in the room but cap the volume of any one voice (reshape the loss); RANSAC decides who is in the room at all (binary membership by consensus), which is why it survives contamination levels that break every loss function. The costs mirror each other: M-estimators need a good start and modest contamination; RANSAC needs a tolerance $\tau$ and enough iterations, and its answer has sampling randomness. The production recipe used across this book is therefore a pipeline: RANSAC to select the inliers, then a least-squares or M-estimator fit on the selected set to measure precisely. Detection robustness and measurement precision are different jobs; assign each to the tool built for it.
Who: A quality engineer at an automotive supplier, responsible for the vision cell that gauges bores on machined brake components.
Situation: A backlit camera images each bore; edge points are extracted along radial profiles at subpixel precision (the parabola-peak trick from Section 9.1) and a circle is fit to report the diameter against a tolerance of ±25 microns, which at the cell's optics is about a third of a pixel.
Problem: Chamfer reflections and occasional swarf produced clusters of false edge points; the least-squares circle fit absorbed them, biasing diameters by up to two pixels on affected parts. The cell was failing good parts and, worse, passing two marginal ones a shift.
Decision: Replace the single fit with the two-step recipe: RANSAC over three-point circle hypotheses (the minimal sample for a circle) with $\tau$ set to 3 times the known edge-point noise, then a final least-squares circle on the consensus set only. Iteration budget from the formula at $w = 0.7$, $p = 0.999$: 18 draws, trivial at line rate.
Result: Diameter repeatability improved from 0.6 pixels to 0.08 pixels (about 6 microns); the gauge passed its repeatability study, false rejects fell by roughly 80 percent, and the false-accept incidents stopped appearing in audit.
Lesson: Subpixel metrology is won or lost at the membership decision, not the fit. The fit was never the problem; the roster was. RANSAC fixed the roster, and ordinary least squares, given an honest roster, was already a superb measuring instrument.
5. Fitting Ellipses Directly Advanced
One conic deserves special mention because it appears whenever circles are photographed: perspective turns circles into ellipses, so pupils, drilled holes, plates, and the calibration dots of Chapter 12 all reach the fitter as ellipse data. The general conic $a x^2 + b x y + c y^2 + d x + e y + f = 0$ is linear in its six coefficients, but a naive least-squares solve happily returns hyperbolas and parabolas when the data is noisy or covers only an arc. Fitzgibbon, Pilu, and Fisher's 1999 method imposes the constraint $4ac - b^2 = 1$, which forces ellipse-ness algebraically, and the constrained problem collapses to a small generalized eigenvalue system: a closed-form, always-an-ellipse fit. That is the algorithm inside OpenCV:
# Fit an ellipse to a pupil blob: extract the largest contour, then let
# cv2.fitEllipse run the Fitzgibbon constrained eigen-solution, which is
# guaranteed to return an ellipse even when the rim is only partly visible.
import cv2
import numpy as np
mask = cv2.imread("pupil_mask.png", cv2.IMREAD_GRAYSCALE) # binary blob
contours, _ = cv2.findContours(mask, cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_NONE)
cnt = max(contours, key=cv2.contourArea) # largest blob's boundary
(cx, cy), (minor, major), angle = cv2.fitEllipse(cnt) # needs >= 5 points
print(f"center ({cx:.1f}, {cy:.1f}), axes {minor:.1f} x {major:.1f} px, "
f"tilt {angle:.1f} deg")
# Representative output:
# center (212.4, 156.8), axes 38.2 x 51.6 px, tilt 14.3 deg
cv2.findContours plus max(..., key=cv2.contourArea) isolates the largest blob's boundary, which feeds cv2.fitEllipse (the Fitzgibbon constrained eigen-solution) to return center, axes, and tilt in one call, guaranteed to be an ellipse even when the contour covers only part of the rim.
The same robustness caveats apply at this level too: cv2.fitEllipse is a least-squares method, so eyelash occlusions or specular bites on the contour call for the RANSAC wrapper (five points is the minimal ellipse sample) or for skimage.measure.EllipseModel inside skimage.measure.ransac, which composes exactly the two-step recipe this section has been building.
Robust fitting remains an active engineering frontier because every multi-view system in Chapter 13 and Chapter 14 lives or dies by it. MAGSAC++ (Barath et al., CVPR 2020) removed RANSAC's most user-hostile knob, the inlier threshold $\tau$, by marginalizing over noise scales, and ships in OpenCV 4.x as part of the USAC framework: passing cv2.USAC_MAGSAC to cv2.findHomography upgrades the estimator with one constant. PARSAC (Kluger and Rosenhahn, AAAI 2024, arXiv:2401.14919) attacks the multi-model setting, several lines or planes at once, with a network that proposes which points belong together, fitting all models in parallel at real-time rates. The broader 2024-2026 pattern is hybridization: learned components propose samples, score consensus, or predict inlier probabilities, while the geometric solvers and the consensus logic of 1981 remain the load-bearing skeleton. Sampling consensus has aged the way Canny has: not replaced, but given better evidence to vote with.
(a) The mean of $n$ numbers has breakdown point 0 while the median survives until half the data is bad; explain in one paragraph how this pair maps onto least squares versus RANSAC. (b) After RANSAC selects a consensus set, the recipe refits with least squares on the inliers; explain why this final fit is now safe, and name the circumstance (think tolerance $\tau$ versus true noise level) under which it still is not. (c) Why does RANSAC fit each hypothesis to a minimal sample rather than, say, ten points?
Generate a synthetic image containing one circle's edge points (200 points, $\sigma = 1$ px) plus 200 uniformly scattered clutter points. Implement RANSAC circle fitting (three-point hypotheses; the circumcenter formula gives the exact circle) and compare against cv2.HoughCircles on a rendering of the same points: report center and radius errors for both, then sweep the clutter count from 0 to 1,000 and plot both methods' errors. Where does each method break first, and how does that match the voting-versus-fitting trade-off from Section 9.3?
Using the formula $N = \ln(1-p) / \ln(1 - w^s)$ with $p = 0.99$, tabulate $N$ for $s \in \{2, 3, 4, 8\}$ and $w \in \{0.8, 0.5, 0.3, 0.1\}$. Then verify one cell empirically: run your line RANSAC 1,000 times at $w = 0.3$ with the tabulated $N$ and report how often it finds the true structure. Finally, explain why the $s = 8$, $w = 0.3$ cell (roughly 70,000 iterations) motivates two strategies you will meet again in Chapter 13: minimal solvers with smaller $s$, and match-quality filtering that raises $w$ before RANSAC ever runs.