"We were supposed to meet at the point. I came in from the left camera, she came in from the right, and we missed each other by half a millimeter, forever. Now a least-squares solver decides where our relationship 'really' was."
A Slightly Skew Triangulation Ray
Triangulation, the final step that turns a verified match into a 3D point, sounds like "intersect two rays" but is really "two noisy rays never intersect, so define the best non-intersection", and the right definition is the one that minimizes error where it actually lives: in the image. This section walks the ladder of answers (midpoint, linear DLT, reprojection-optimal), implements them, and wires the chapter's full toolkit into a working two-view reconstructor: matches to essential matrix to pose to point cloud, with the cheirality and parallax checks that keep the output honest. This pipeline, run pairwise and stitched globally, is the inner loop of Chapter 14's structure from motion.
Section 13.5 recovered depth densely, but only for the rectified, calibrated, short-baseline world of stereo rigs. The general problem is sparser and wilder: two arbitrary cameras, poses recovered by Section 13.2's essential-matrix machinery, and a few thousand verified matches from Chapter 10. Each match nominates two rays in space; geometry says they should cross at the scene point. Then measurement noise has its say.
1. Why the Rays Miss Beginner
Each detected keypoint is off by some fraction of a pixel (recall the sub-pixel refinement battles of Chapter 10); each camera pose carries its own estimation error. Back-project two such corrupted measurements and you get two lines in 3D space, and two lines in 3D, unlike two lines in a plane, generically do not intersect at all: they pass by each other, skew, at some closest-approach distance. "The triangulated point" is therefore a decision, not an observation, and Figure 13.6.1 shows both the decision and the geometry that controls its quality: the angle between the rays. (The illustration below tells the same story with a touch of comedy: two rays that miss forever, a referee splitting the gap, and a shallow angle that turns the guess wild.)
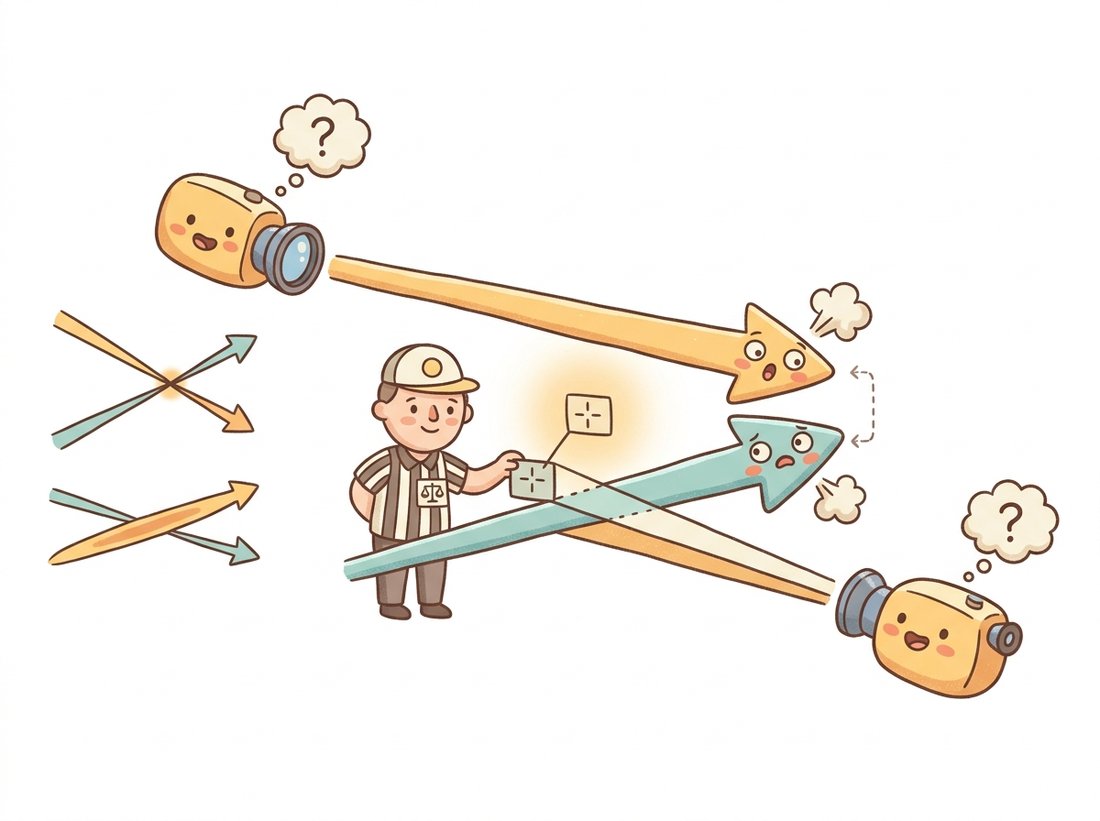
The right panel of Figure 13.6.1 is the section's recurring warning. When the parallax angle between rays is small (short baseline relative to depth), pixel noise barely changes where the rays are but enormously changes where they nearly cross: the uncertainty region stretches into a sliver along the viewing direction. This is Section 13.5's quadratic law wearing general-geometry clothes, and it is why every serious pipeline filters triangulated points by parallax angle before trusting them.
2. The Midpoint Method Intermediate
The estimate drawn in Figure 13.6.1's left panel is the midpoint method: find the unique points $\mathbf{p}_1 = \mathbf{C}_L + s\,\mathbf{r}_L$ and $\mathbf{p}_2 = \mathbf{C}_R + u\,\mathbf{r}_R$ minimizing $\lVert \mathbf{p}_1 - \mathbf{p}_2 \rVert$ (two linear equations from perpendicularity of the connecting segment to both rays), and return their midpoint. It is intuitive, fast, and fine for visualization or initialization. Its weakness is principle: it minimizes a distance in 3D space, where errors are anisotropic and depth-dependent (that sliver again), so it silently weights distant points' wild depth axes the same as their well-measured lateral axes. The measurements we actually trust live in the image plane, which suggests minimizing there instead.
The noise model owns the objective. Keypoint detectors err by roughly Gaussian fractions of a pixel in the image; nothing errs "in 3D", because 3D was never measured. The statistically right estimate of $\mathbf{X}$ therefore minimizes reprojection error, the summed squared image distance between each observation and the reprojection of the candidate point, $\sum_i \lVert \mathbf{x}_i - \pi(P_i \mathbf{X}) \rVert^2$. This single principle organizes the entire reconstruction stack: Hartley and Sturm's optimal two-view triangulation solves it exactly (a degree-6 polynomial), nonlinear refinement solves it iteratively from a linear initialization, and Chapter 14's bundle adjustment is nothing but the same objective minimized over all points and all cameras at once. When in doubt about any geometric estimate in vision, ask what it costs in reprojected pixels.
3. Linear Triangulation: The DLT Again Advanced
The workhorse algorithm is the linear one, and it recycles this chapter's favorite move (one homogeneous equation set, one SVD null space). A camera with $3 \times 4$ projection matrix $P$ maps the homogeneous point $\mathbf{X}$ to $\mathbf{x} \sim P\mathbf{X}$; "equal up to scale" means $\mathbf{x}$ and $P\mathbf{X}$ point in the same direction, and two parallel vectors have a zero cross product, so $\mathbf{x} \times P\mathbf{X} = \mathbf{0}$, giving two independent linear equations per view. Stack the four equations from two views into $A\mathbf{X} = \mathbf{0}$ and take the SVD null vector, exactly as in the eight-point algorithm of Section 13.2 and the homography DLT of Section 13.3:
# Linear (DLT) triangulation: each view contributes the cross-product
# equation x cross PX = 0, and the SVD null space of the stacked system is
# the 3D point. The same construction runs vectorized in triangulatePoints.
import cv2
import numpy as np
def triangulate_dlt(P1, P2, x1, x2):
"""One 3D point from one match. P1, P2: 3x4. x1, x2: pixel coords."""
A = np.stack([
x1[0] * P1[2] - P1[0], # x * (row 3) - (row 1) = 0
x1[1] * P1[2] - P1[1], # y * (row 3) - (row 2) = 0
x2[0] * P2[2] - P2[0],
x2[1] * P2[2] - P2[1]])
_, _, Vt = np.linalg.svd(A)
X = Vt[-1]
return X[:3] / X[3] # dehomogenize
# left camera at origin, right camera from Section 13.2's recoverPose
P1 = K @ np.hstack([np.eye(3), np.zeros((3, 1))])
P2 = K @ np.hstack([R, t.reshape(3, 1)])
X = triangulate_dlt(P1, P2, ptsL[0], ptsR[0])
print(np.round(X, 3)) # e.g. [-0.214 0.078 3.642]
# the same, vectorized over all matches, via OpenCV
Xh = cv2.triangulatePoints(P1, P2, ptsL.T.astype(np.float64),
ptsR.T.astype(np.float64))
pts3d = (Xh[:3] / Xh[3]).T # Nx3triangulate_dlt stacks the two cross-product equations $\mathbf{x} \times P\mathbf{X} = \mathbf{0}$ from each view into a $4 \times 4$ system A whose SVD null vector Vt[-1] is the homogeneous 3D point, dehomogenized by X[:3] / X[3]. The vectorized cv2.triangulatePoints runs the identical construction across all matches at once, returning $4 \times N$ coordinates that still need the divide-by-$w$.
Caveats that bite in practice: cv2.triangulatePoints wants points as $2 \times N$ arrays and returns homogeneous $4 \times N$ output, and forgetting the divide-by-$w$ is a rite of passage. The linear solve minimizes an algebraic quantity, not reprojection error; with Hartley normalization of image coordinates it is typically within a whisker of optimal at sane parallax, and a few Gauss-Newton steps on the reprojection objective (or Hartley-Sturm's exact polynomial method for the two-view case) close the remaining gap when millimeters matter. Because the result is computed in homogeneous coordinates, a point can come back with $w$ of the sign that places it behind a camera, which is not a bug but a verdict: that match was wrong, and the check belongs in the pipeline.
4. The Complete Two-View Reconstructor Intermediate
Everything this chapter built now snaps together into a single pipeline: matches (Chapter 10), essential matrix and pose (Section 13.2), triangulation (this section), and the two filters this section has motivated: cheirality (positive depth in both cameras, the same test that picked the true pose from four candidates) and parallax angle (discard the slivers). Calibration $K$ comes from Chapter 12.
def two_view_reconstruct(ptsL, ptsR, K, min_parallax_deg=1.5):
"""Matches + intrinsics -> relative pose and a filtered 3D point set."""
E, mask = cv2.findEssentialMat(ptsL, ptsR, K,
method=cv2.USAC_MAGSAC,
prob=0.999, threshold=1.0)
_, R, t, pose_mask = cv2.recoverPose(E, ptsL, ptsR, K, mask=mask)
keep = pose_mask.ravel().astype(bool)
pL, pR = ptsL[keep], ptsR[keep]
P1 = K @ np.hstack([np.eye(3), np.zeros((3, 1))])
P2 = K @ np.hstack([R, t])
Xh = cv2.triangulatePoints(P1, P2, pL.T.astype(np.float64),
pR.T.astype(np.float64))
X = (Xh[:3] / Xh[3]).T
# cheirality: positive depth in BOTH camera frames
z1 = X[:, 2]
z2 = (R @ X.T + t).T[:, 2]
ok = (z1 > 0) & (z2 > 0)
# parallax: angle between the two viewing rays at each point
r1 = X / np.linalg.norm(X, axis=1, keepdims=True)
C2 = (-R.T @ t).ravel() # right camera center
r2 = X - C2
r2 /= np.linalg.norm(r2, axis=1, keepdims=True)
cosang = np.clip((r1 * r2).sum(axis=1), -1, 1)
ok &= np.degrees(np.arccos(cosang)) > min_parallax_deg
return R, t, X[ok], ok.sum() / len(X)
R, t, cloud, keep_frac = two_view_reconstruct(ptsL[inl], ptsR[inl], K)
print(f"{len(cloud)} points kept ({100 * keep_frac:.0f}%), "
f"baseline direction {t.ravel().round(2)}")
# 1147 points kept (83%), baseline direction [-0.97 0.03 0.24]two_view_reconstruct chains cv2.findEssentialMat, cv2.recoverPose (with its internal cheirality vote), and batch cv2.triangulatePoints, then applies the two trust filters that separate measured structure from geometric noise: positive depth z1 and z2 in both camera frames, and a parallax angle above min_parallax_deg computed from the per-point viewing rays. The returned cloud is metric only up to the global scale of $\lVert \mathbf{t} \rVert$, which recoverPose fixes to unit length.
Two properties of the output deserve flagging. The cloud is scaleless: recoverPose returns $\mathbf{t}$ as a unit vector, so the reconstruction floats at an arbitrary global scale until something metric pins it (a known baseline as in Section 13.5, a known object size, GPS, or an IMU). And it is sparse and view-dependent: points exist only where Chapter 10 found matchable texture. Both limitations are the opening brief for Chapter 14, which chains many pairs, shares scale through overlapping views, and polishes everything with bundle adjustment; the densification story then continues into the multi-view stereo and neural fields of Chapter 27.
Within a script, cv2.triangulatePoints(P1, P2, x1, x2) replaces the 12-line DLT with one vectorized call (plus your dehomogenization), and cv2.sfm in opencv-contrib offers triangulatePoints for $N$-view tracks. But the honest library shortcut for "I have a folder of images and want 3D" is a level higher: COLMAP runs this entire section (plus Chapter 10's matching and Chapter 14's bundle adjustment) behind one command, colmap automatic_reconstructor --image_path imgs --workspace_path out, reducing a few hundred lines of careful pipeline to zero while adding track building, incremental pose chaining, outlier-aware multi-view triangulation with exactly this section's parallax checks, and global refinement. The two-view code above is still the right tool when you need a fast pairwise depth probe inside a larger system, and the only tool when you need to understand why COLMAP rejected half your images.
Who: A drone-inspection company reconstructing wind-turbine blades for crack measurement, contracted to localize defects to within 5 mm.
Situation: The drone orbited each blade capturing overlapping photos; a two-view module triangulated surface points between consecutive frames to seed the dense model.
Problem: Blade-tip reconstructions showed centimeter-scale "breathing": surface points scattered several centimeters along the viewing direction, while the blade root reconstructed beautifully. The matches were excellent in both regions; the team initially blamed the matcher anyway and burned a week tightening it.
Decision: Plotting triangulation parallax angles told the real story: near the slim blade tip the pilot had widened the orbit for safety clearance, so consecutive frames viewed tip points just 0.4 degrees apart, the sliver regime of Figure 13.6.1, against 4 degrees at the root. The fix was capture-side and software-side at once: a flight-plan rule enforcing a minimum triangulation angle of 2 degrees (skip frames until the angle clears it), plus the parallax filter from this section's pipeline so under-angled points seed nothing downstream.
Result: Tip surface noise fell from 31 mm RMS to 3.2 mm, meeting spec without any matcher changes. The "minimum parallax" rule went into the company's flight-planning checklist alongside battery margins.
Lesson: Triangulation precision is set at capture time by geometry, not at compute time by code. When a reconstruction is noisy along viewing rays specifically, audit the angles before the algorithms.
The 2024-2026 wave already met in Section 13.1 reaches its logical endpoint here. DUSt3R (CVPR 2024) outputs dense per-pixel 3D pointmaps for an image pair directly, in effect performing matching and triangulation jointly inside a transformer, and MASt3R (ECCV 2024) sharpens the matching head until classical solvers can be run on its correspondences as a cross-check of its own geometry. VGGT (CVPR 2025) scales the recipe to long sequences, regressing cameras, depth maps, and point tracks in a single feed-forward pass at speeds incremental pipelines cannot touch. Yet the classical machinery refuses retirement for three reasons worth knowing. Metric integrity: feed-forward pointmaps inherit their scale and calibration priors from training data, while two-view triangulation with a measured baseline is metric by construction. Auditability: a triangulated point's reprojection error (the principle of this section's Key Insight) is a per-point certificate that regulators and engineering customers can check; a pointmap's confidence channel is a learned opinion. And hybrid reality: the strongest 2025-2026 systems initialize or regularize learned predictions with classically triangulated anchors, and 3D Gaussian Splatting pipelines (Chapter 27) still overwhelmingly begin from a COLMAP sparse cloud, which is to say: from this section, run well.
Construct (on paper, with a sketch) a two-view configuration in which the midpoint estimate and the reprojection-optimal estimate of the same match differ substantially: place one camera much farther from the point than the other, and reason about how each objective weighs a fixed pixel error in the near versus the far view. Which estimate moves toward the near camera's ray, and why is that the statistically defensible behavior? Then explain why the two estimates nearly coincide for a symmetric, wide-parallax stereo pair.
Build a synthetic experiment: place a 3D point at depth 10 (arbitrary units), two cameras with $f = 800$ px separated by a baseline you will vary so the parallax angle spans 0.2 to 20 degrees, project the point into both views, add Gaussian pixel noise ($\sigma = 0.5$), and triangulate with this section's triangulate_dlt over 2,000 noise draws per angle. Plot the standard deviation of the recovered point along the viewing direction and perpendicular to it, against parallax angle, on log-log axes. At what angle does the along-ray error exceed 10x the lateral error, and how does your curve justify the turbine team's 2-degree rule?
Run two_view_reconstruct on a pair of photos of a textured 3D scene taken roughly 10 to 20 degrees apart with a calibrated camera, export the cloud as PLY (reuse Section 13.5's writer), and audit it three ways: (a) compute the reprojection error of every kept point in both views and report the median and 95th percentile; (b) histogram the parallax angles and relate their spread to the cloud's visual quality in MeshLab; (c) measure a known object in the cloud, derive the scene's true scale factor, and verify that one scalar multiplication metricizes your whole reconstruction. Report which of the three audits would have caught a hypothetical bug where $\mathbf{t}$ was accidentally negated.