"I was trained on the open web, my weights carry a license I did not read, and my outputs belong to someone the law has not yet decided on. I generate beautiful images and an equal volume of unresolved legal questions."
A Generative Model Awaiting a Court Ruling
A generative vision system carries three stacked legal and ethical questions that engineering alone cannot answer: what you were allowed to train on, what license governs the weights you use, and who (if anyone) owns the images you produce, all sitting on top of the unresolved memorization and consent problems. Training-data provenance and model-weight licenses are concrete and checkable; the copyright status of generated images and the fair-use status of training are genuinely unsettled and being decided in courts as you read this. Responsible deployment does not require resolving the open questions; it requires knowing which questions are settled, which are open, and building a system whose data, weights, outputs, and safeguards you can actually account for. This section turns that into a checklist and an audit you can run.
Detection and provenance (Sections 37.4 and 37.5) governed what an image is and where it came from; the last layer of governance is what the law allows you to do with it. This is the final section of the part, and it is deliberately not about a new model. Every generator you built across Part IV (VAEs, GANs, diffusion, text-to-image) was trained on data someone collected, ships under a license someone wrote, and produces outputs someone will use. Those facts have legal weight, and a system that ignores them is not deployable no matter how good its FID. The goal here is literacy, not legal advice: enough understanding to ask the right questions, document the right things, and know when to call a lawyer. The questions are real, the stakes are real, and the engineer who can reason about them is the one whose project ships.
1. The Three-Layer Stack Beginner
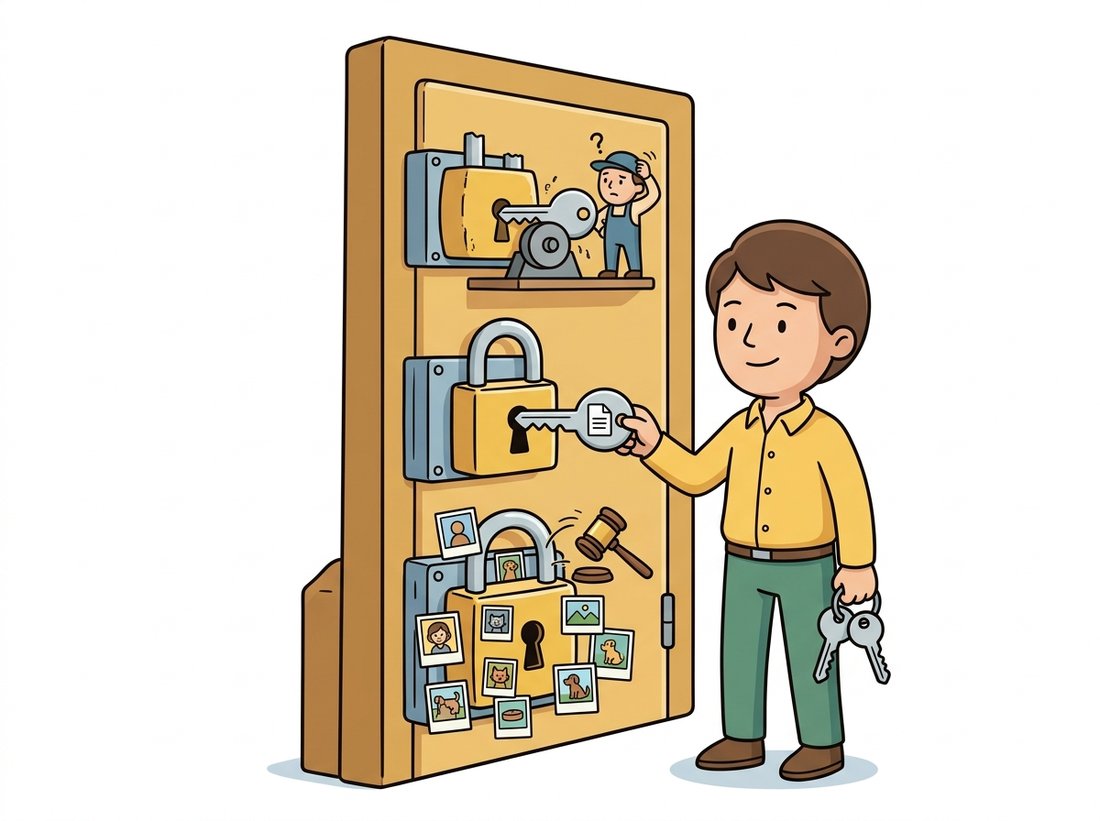
Untangling the legal picture starts with separating three distinct layers, each with its own rules, that people routinely confuse. Figure 37.6.1 stacks them.
- Training data. What was the model trained on, and under what terms? A model trained on a licensed dataset (or genuinely public-domain images) stands on firm ground; one trained on web-scraped images of unknown provenance inherits whatever rights problems that data carries. This is the layer most actively litigated.
- Model weights. The trained weights ship under a license that constrains how you may use them. "Open weights" is not the same as "open source" or "unrestricted," as subsection 2 details.
- Generated outputs. Who owns an image the model produces, and can it be copyrighted at all? This is genuinely unsettled and depends on jurisdiction and on how much human authorship was involved.
2. Model and Data Licenses in Practice Intermediate
"Open weights" means the weights are downloadable; it does not mean you may do anything with them. Many popular generative models ship under responsible-AI licenses (the OpenRAIL family used by early Stable Diffusion, for example) that grant broad use but prohibit specific harmful applications, and others ship under custom commercial licenses with thresholds (free below a revenue or user count, paid above). Conflating "I can download it" with "I can build a paid product on it" is a frequent and expensive mistake. Datasets carry their own terms, and an image's presence in a research dataset like LAION (which distributes URLs and captions, not the images themselves) does not transfer any usage right in the underlying images. The practical discipline is to read the actual license file of every model and dataset you depend on and record what it permits, before you build on it. The code below is a literacy aid that classifies the common license families a model card might declare.
def classify_license(license_id):
"""Map a model/dataset license string to its practical constraints.
Educational helper, NOT legal advice: always read the actual license.
"""
lid = license_id.lower()
if "openrail" in lid or "rail" in lid:
return ("Responsible-AI license: broad use permitted, "
"specific harmful uses prohibited; check the use-restriction list.")
if "cc-by" in lid and "nc" in lid:
return "Creative Commons NonCommercial: no commercial use without permission."
if "cc-by" in lid:
return "Creative Commons Attribution: commercial use OK with attribution."
if "apache" in lid or "mit" in lid:
return "Permissive open source: broad commercial use, keep the notice."
if "research" in lid or "non-commercial" in lid:
return "Research-only: NOT for commercial deployment."
return "Unknown / custom license: read it in full and likely consult counsel."
for lic in ["CreativeML-OpenRAIL-M", "cc-by-nc-4.0", "apache-2.0", "custom-research"]:
print(f"{lic:24s} -> {classify_license(lic)}")
The single most consequential misconception in applied generative AI is that an openly downloadable model or a publicly visible image is free to use however you like. Open weights come with licenses that can forbid commercial use, certain application domains, or redistribution; public images on the web retain their authors' copyright. The fact that a tool makes something technically easy to obtain says nothing about whether you are legally permitted to build on it. Treat every dependency's license as a contract you have signed, because in effect you have.
"It was on the internet" has the same legal force as "the door was unlocked." Downloadable is not unrestricted; visible is not free; and a license is a contract you signed by reading nothing, which is the worst kind to sign. The three layers fail people because they look like one question and are really three with different answers: you can settle two by reading a file today, and the third you can only wait on a judge for. Signature phrase for the section: data, weights, outputs: three locks, three keys, and only one of them is still being cut.
3. The Copyright Questions That Are Genuinely Open Advanced
Two questions sit unresolved at the heart of generative vision, and honesty requires marking them as open rather than pretending engineering settles them. First, is training on copyrighted images fair use? (Fair use is the US legal doctrine, with rough analogues elsewhere, that permits limited unlicensed use of copyrighted work when the use is sufficiently transformative; whether model training qualifies is the contested point.) Model developers argue that learning statistical patterns from images is transformative and analogous to a human studying art; rights-holders argue it is mass unlicensed copying that competes with the originals.
The question remains unresolved for image generators specifically: the artists' class action Andersen v. Stability AI survived dismissal and is scheduled for trial in September 2026, and in Getty Images v. Stability AI the English High Court ruled in November 2025 on narrow trademark grounds while declining the core copyright claims, holding that the trained model weights are not themselves a "copy" of the training images. Mid-2025 fair-use wins in text-model cases point one way: in Bartz v. Anthropic and Kadrey v. Meta, both decided in June 2025, training was held transformative. But those rulings turned on facts specific to text and books, so they do not settle the image question, and their reasoning split on whether the source copies were lawfully acquired in the first place. The outcomes still pending will reshape what training data is permissible.
Second, can a purely AI-generated image be copyrighted, and by whom? Guidance in several jurisdictions (notably the US Copyright Office) currently holds that output lacking sufficient human authorship is not copyrightable, while images with substantial human creative control over the process may be, leaving a blurry, evolving line. The engineer's job is not to resolve these but to know they are live, to track the jurisdiction the product operates in, and to design so that a future ruling does not strand the system.
4. Memorization and Consent Advanced
A specific technical fact sharpens the legal abstractions: generators can memorize and regurgitate individual training images. Here the abstraction becomes uncomfortably concrete. Carlini et al. (2023) typed a caption that appeared often in Stable Diffusion's training set, and the model handed back a near-pixel-perfect copy of the exact training photograph behind that caption, the same person, the same pose, the same background. For those prompts the "generator" was not generating at all; it was acting as a lossy copy machine for an image it had seen. That is the whole abstract training-data debate collapsed into a single screenshot: a model that learned "general statistics" and a model that quietly stored your photograph look identical until someone types the right words. Memorization is most likely for duplicated or rare-and-captioned images, and it converts the abstract training-data question into a concrete one: a model that can reproduce a copyrighted photo on demand is a different legal object from one that has only learned general statistics. This intersects with consent: training data scraped from the web includes images of real people who never agreed to be in a training set, and faces in particular (the focus of the deepfake harms in Section 37.4) raise privacy and likeness-rights issues distinct from copyright. A responsible deployment measures its model's memorization rather than assuming it away, and the audit below operationalizes that.
import torch
@torch.no_grad()
def memorization_check(generated_feats, training_feats, threshold=0.95):
"""Flag generated images that are near-duplicates of a training image.
Both inputs: L2-normalized feature vectors (e.g. CLIP or DINOv2),
[N, D] generated and [M, D] training. Returns indices of likely
memorized outputs and their nearest training match.
"""
sims = generated_feats @ training_feats.T # cosine, both normalized
best_sim, best_idx = sims.max(dim=1) # nearest training image
flagged = (best_sim >= threshold).nonzero(as_tuple=True)[0]
return [(int(i), int(best_idx[i]), float(best_sim[i])) for i in flagged]
# Run a batch of generations against the training set BEFORE shipping.
# hits = memorization_check(gen_feats, train_feats, threshold=0.95)
# for g, t, s in hits:
# print(f"generated {g} ~ training {t} (cos={s:.3f}) -> review/suppress")
Who: the creative-technology team at an advertising agency, 2025, building an internal text-to-image tool for client campaigns. Situation: clients demanded indemnification, that the agency guarantee the generated imagery would not trigger copyright claims. Problem: the best open model was trained on web-scraped data of unknown provenance and shipped under a license whose commercial terms were ambiguous, and the legal team would not sign off on it for client work. Decision: they switched to a model trained on a fully licensed image corpus (the "indemnified" commercial generators that several vendors began offering in 2023 to 2024 precisely for this market), recorded the data and weight licenses per the three-layer stack of subsection 1, and ran the memorization audit of subsection 4 on every batch before delivery, suppressing flagged near-duplicates. Result: the legal team approved the tool for client campaigns, the indemnification clause was honored by the model vendor, and the memorization audit caught a handful of near-duplicates of stock photos that would otherwise have shipped. Lesson: the legal questions were not resolved in the abstract, but accountability at all three layers (licensed data, clear weight license, audited outputs) made the system deployable in a setting where an unaudited model could not have been used at all.
5. A Responsible-Deployment Checklist Intermediate
Pulling the chapter together, responsible deployment of a generative vision system is a matter of accounting for every layer you can control and being honest about the ones you cannot. The checklist below is the practical synthesis of all six sections of this chapter:
- Evaluation (37.1, 37.2). Report distribution metrics (FID or KID) and prompt alignment (CLIPScore) together, and back consequential decisions with a powered human study, not a hallway glance.
- Data engine (37.3). If you train on synthetic data, anchor it with real data, validate on real data, and watch for model collapse.
- Provenance (37.5). Watermark generated outputs (preferably in-generation) and attach C2PA manifests, so your content can prove its origin.
- Misuse (37.4). Assess the realistic threat model for your use case, gate sensitive capabilities (face generation, identity editing), and treat detectors as one fallible layer.
- Legal (this section). Document the training-data provenance, the model and dataset licenses, and the output-ownership posture; run a memorization audit; and track the jurisdictions you operate in.
None of these requires resolving the open questions of subsection 3. They require knowing where the open questions are and building a system you can stand behind. That accountability, across measurement, deployment, and governance, is what turns the generators of Part IV from a research demo into something you can ship.
The 2024 to 2026 frontier here blends technical research with fast-moving regulation. On the technical side, machine unlearning for generative models (erasing a specific concept, style, or memorized image from a trained model without full retraining, as in Gandikota et al.'s "Erasing Concepts from Diffusion Models," ICCV 2023, arXiv:2303.07345) aims to make a model forget data it should not have learned, and training-data attribution methods try to trace which training images most influenced a given output. On the policy side, the EU AI Act's transparency and training-data-summary obligations (the Article 50 marking duties become enforceable on 2 August 2026) and ongoing US and UK rulemaking are turning provenance, disclosure, and data documentation into legal requirements rather than best practices, and the 2025 wave of court decisions (transformative-use findings for text-model training, alongside the still-open image-generator cases of subsection 3) has begun to draw the fair-use line without yet settling it. The synthesis the field is converging on, and the note to end Part IV on, is that the durable generative systems will be the ones built for accountability from the start: licensed or documented data, auditable outputs, embedded provenance, and the technical means to unlearn what they should not have known.
For a hypothetical product that uses an openly downloadable diffusion model to generate marketing images, write one sentence each on the three layers of subsection 1: what you would need to check about the training data, the weight license, and the output ownership. Then identify which of the three is genuinely unsettled in law and which two you can resolve today by reading documents, and explain why conflating them leads to wrong conclusions.
Take a small image dataset as a stand-in training set and a batch of generated (or simply held-out real) images as the "outputs." Embed both with a CLIP image encoder, normalize the features, and run memorization_check from subsection 4 at thresholds 0.90, 0.95, and 0.99. Report how the number of flagged near-duplicates changes with the threshold, and discuss in two sentences how you would choose an operating threshold for a real deployment given the tradeoff between catching memorized content and over-flagging.
Pick a real generative image model on the Hugging Face hub and read its model card and license. Using the framework of this section, write a short assessment covering: what the card discloses about training data, what the weight license permits and forbids (run its license string through classify_license from subsection 2 as a starting point), what it says about generated-output ownership or watermarking, and whether you could responsibly deploy it in a paid product. Conclude with the single most important missing piece of information you would need before deploying.